前言:为什么系统设计面试让你头疼?
我第一次参加系统设计面试时,一上来面试官就说”设计一个微博”。当时脑子一片空白,随便画了几个方框就开始说,结果可想而知——面试结束后我连自己说了什么都不记得。
后来我自己当了面试官才发现,系统设计面试考察的从来不是”标准答案”,而是你思考问题的方式。一个好的系统设计师,需要在有限时间内:
- 理解需求的本质
- 快速识别核心问题
- 有条理地分解复杂系统
- 做出合理的技术权衡
今天就把我的面试官视角和备战经验分享出来,帮你系统性地准备系统设计面试。
系统设计面试考察什么?
面试官在系统设计面试中主要考察三个方面:
结构化思维能力:你能否将一个模糊、宏大的问题,拆解成具体的、可执行的模块?有没有一套清晰的分析框架?
技术权衡能力:技术世界没有银弹。每个选择都有利有弊,你能否清晰分析不同方案的优缺点,并根据业务场景做出合理的取舍?
知识广度与深度:你是否了解构建现代化分布式系统的”积木”?负载均衡、CDN、缓存、数据库、消息队列——这些组件你理解有多深?
第一部分:系统设计的核心概念
在开始解题之前,必须先理解衡量系统优劣的通用标准。
SPARCS原则
评价一个系统设计,可以用这个缩写——SPARCS:
S – Scalability(可扩展性)
系统应对负载增长的能力。有两种扩展方式:
- 垂直扩展(Scale Up):给单机增加更多CPU、内存
- 水平扩展(Scale Out):增加更多服务器
python
# 垂直扩展示例:增加服务器配置
server = {
'cpu': 64, # 原来是8核
'ram': 256, # 原来是32GB
'storage': 2TB
}
# 水平扩展示例:增加服务器数量
servers = [
Server(),
Server(), # 新增服务器
Server() # 再新增服务器
]
P – Performance(性能)
系统利用最少资源完成既定任务的能力。通常用延迟(Latency)和吞吐量(Throughput)来衡量:
- 延迟:请求发出到收到响应的时间,如Feed流加载<200ms
- 吞吐量:单位时间内处理的请求数,如10万QPS
A – Availability(可用性)
系统正常运行并可供用户访问的时间比例,通常用”几个9″来衡量:
- 99.9%(3个9):每年停机约8.7小时
- 99.99%(4个9):每年停机约52分钟
- 99.999%(5个9):每年停机约5分钟
R – Reliability(可靠性)
系统在规定条件下无故障执行的能力。可靠的系统就像值得信赖的朋友,每次都能给出正确的回应。
C – Consistency(一致性)
在分布式系统中,指数据在多个副本之间保持同步的状态:
- 强一致性:任何时刻所有节点数据一致
- 最终一致性:允许短暂不一致,但最终会同步
S – Security(安全性)
系统保护数据不被未授权访问的能力,包括认证、授权、数据加密等。
常见的权衡困境
这些指标之间经常存在冲突,你需要根据业务场景权衡:
| 场景 | 常见权衡 |
|---|---|
| 高并发读取 | 一致性 vs 性能 |
| 数据可靠存储 | 延迟 vs 持久性 |
| 全球部署 | 一致性 vs 可用性 |
| 实时更新 | 延迟 vs 准确性 |
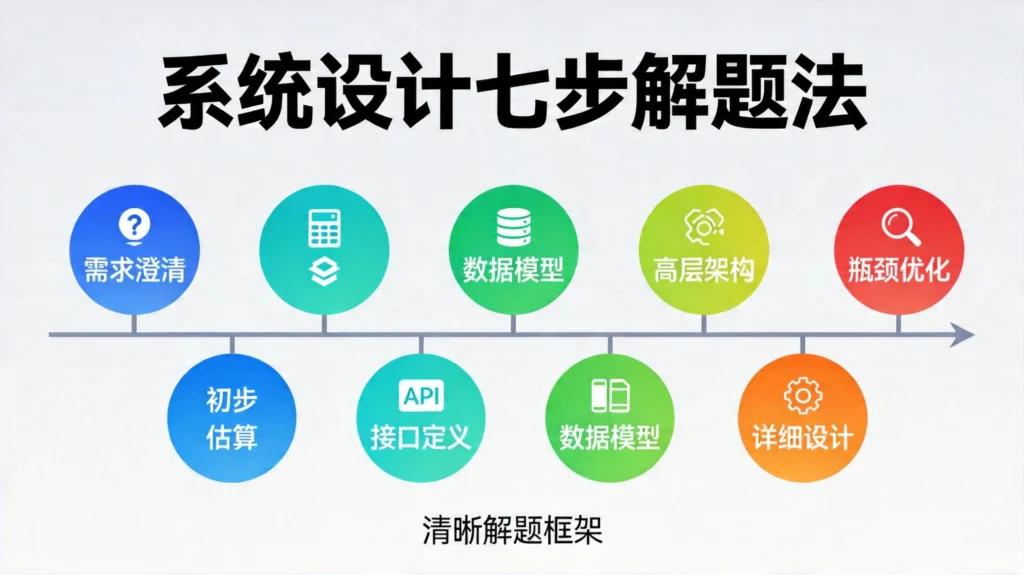
第二部分:七步解题法框架
面对任何系统设计题,遵循这个结构化的七步框架,能引导你与面试官进行有条理的对话。
步骤一:需求澄清(0-5分钟)
这是最关键也最容易被忽略的一步。不要假设,要提问!
你需要澄清两类需求:
功能性需求:用户能用系统做什么?
plaintext
例如设计一个微博:
- 用户可以发布动态(文字、图片、视频)
- 用户可以关注/取关其他用户
- 用户可以浏览自己和所关注人的动态(Feed流)
- 用户可以对内容点赞、评论、转发
非功能性需求:系统需要满足哪些质量标准?
plaintext
高可用性:系统不能轻易宕机
高性能:Feed流加载<200ms
可扩展性:能支持1亿日活用户
一致性:点赞数可以稍有不一致但最终一致
把这些写在白板上,就相当于和面试官形成了”设计合约”。
步骤二:初步估算(5-10分钟)
根据需求进行简要的量化分析,帮助你判断技术选型方向。
关键估算公式:
plaintext
写QPS = 日活用户 × 平均发帖数 / 86400秒
读QPS = 日活用户 × 平均浏览数 / 86400秒
峰值QPS ≈ 平均QPS × 2-3倍
实例估算(设计微博):
plaintext
假设:1亿DAU,每个用户每天平均发0.1条动态,看100条动态
写QPS = 1亿 × 0.1 / 86400 ≈ 115 QPS
读QPS = 1亿 × 100 / 86400 ≈ 115,000 QPS
结论:这是一个典型的读多写少系统,读QPS是瓶颈
步骤三:系统接口定义(10-15分钟)
明确系统需要对外提供的API接口:
python
# API设计示例
POST /api/v1/posts # 发布动态
GET /api/v1/feed # 获取Feed流
POST /api/v1/posts/{id}/like # 点赞
POST /api/v1/users/{id}/follow # 关注用户
GET /api/v1/users/{id} # 获取用户信息
每个接口需要定义:
- 请求参数和格式
- 返回结果和格式
- 错误码和处理方式
步骤四:数据模型设计(15-25分钟)
设计核心数据对象的结构以及它们之间的关系:
sql
-- 用户相关表
CREATE TABLE users (
user_id BIGINT PRIMARY KEY,
username VARCHAR(50),
created_at TIMESTAMP
);
-- 关注关系(复合主键避免重复关注)
CREATE TABLE follows (
follower_id BIGINT,
followed_id BIGINT,
created_at TIMESTAMP,
PRIMARY KEY (follower_id, followed_id)
);
-- 动态表
CREATE TABLE posts (
post_id BIGINT PRIMARY KEY,
user_id BIGINT,
content TEXT,
created_at TIMESTAMP
);
-- 点赞表
CREATE TABLE likes (
user_id BIGINT,
post_id BIGINT,
created_at TIMESTAMP,
PRIMARY KEY (user_id, post_id)
);
关键选择:
- SQL vs NoSQL:根据一致性需求选择
- 索引设计:哪些字段需要经常查询?
- 数据量预估:每张表会有多少数据?
步骤五:高层架构设计(25-35分钟)
绘制系统的宏观架构图:
plaintext
┌─────────────┐
│ Clients │ (Mobile / Web)
└──────┬──────┘
│
▼
┌─────────────┐
│ CDN / Cache │ (分发静态资源 + 热门内容)
└──────┬──────┘
│
▼
┌──────────────┐ ┌──────────────┐
│Load Balancer │────▶│Load Balancer │ (负载均衡)
└──────┬───────┘ └──────┬───────┘
│ │
▼ ▼
┌─────────────┐ ┌─────────────┐
│ API Servers │ │Media Service│ (业务逻辑 / 媒体处理)
└──────┬──────┘ └──────┬──────┘
│ │
▼ ▼
┌─────────────┐ ┌─────────────┐
│ Database │ │Object Storage│ (MySQL/PG / S3/OSS)
└─────────────┘ └─────────────┘
讲解数据流向,让面试官形成清晰的”系统鸟瞰图”。
步骤六:详细设计(35-45分钟)
与面试官深入探讨1-2个核心组件的细节。根据前面的估算,识别系统瓶颈,然后讨论优化方案。
以微博Feed流为例,可能深入讨论:
python
# 方案1:推模式(Fan-out on Write)
# 发帖时,把动态写入所有粉丝的Timeline
# 优点:读取快(直接读Timeline)
# 缺点:写入慢(明星发帖可能需要写1亿条)
# 方案2:拉模式(Fan-out on Read)
# 读取时,聚合所有关注对象的动态
# 优点:写入快
# 缺点:读取慢(需要查询所有关注的人)
# 方案3:混合模式(推荐)
# 普通用户:推模式(粉丝少,写入可控)
# 明星用户:拉模式(粉丝多,避免写入爆炸)
# 或者:写扩散 + 缓存热点用户的Timeline
步骤七:瓶颈识别与优化(45-50分钟)
主动审视设计,找出潜在的性能瓶颈或单点故障:
常见瓶颈识别:
plaintext
数据库读压力 → 引入Redis缓存 + 读写分离
数据库写压力 → 分库分表 + 异步写入
单点故障 → 主从切换 + 多机房部署
热点数据 → 本地缓存 + 热点探测
网络带宽 → CDN加速 + 数据压缩
第三部分:高频面试题型
根据我的面试经验,以下是出现频率最高的系统设计题目:
第一梯队:必考题
1. 设计一个短链接服务(如TinyURL)
- 核心点:哈希算法、唯一ID生成、存储选型、重定向
- 延伸点:流量高峰处理、链接过期策略
2. 设计一个Twitter/微博Feed流
- 核心点:推拉模式、数据模型、分页设计
- 延伸点:点赞评论计数、排序算法
3. 设计一个消息推送系统
- 核心点:设备管理、长连接、消息存储
- 延伸点:离线消息、推送策略
4. 设计一个视频分享平台(如YouTube)
- 核心点:上传流程、转码、CDN分发
- 延伸点:缩略图生成、推荐系统
第二梯队:高频题
5. 设计一个即时通讯系统
- 核心点:长连接、WebSocket、消息顺序
- 延伸点:已读未读、端到端加密
6. 设计一个搜索建议系统
- 核心点:Trie树、缓存策略、实时性
- 延伸点:纠错功能、搜索排序
7. 设计一个分布式爬虫系统
- 核心点:URL去重、任务调度、深度控制
- 延伸点:反爬策略、资源限制
8. 设计一个限流器
- 核心点:计数器、滑动窗口、令牌桶
- 延伸点:分布式限流、自适应限流
第四部分:面试技巧与注意事项
积极沟通
边想边说:不要长时间沉默思考。把你的思考过程说出来,让面试官了解你的思路。
主动确认:每做一步决定前,简要说明理由。”我打算用Redis做缓存,因为读多写少场景下缓存命中率很高,这样可以把延迟从50ms降到5ms。”
引导对话:你不是在被动回答问题,而是主导设计方向。如果感觉走偏了,可以问面试官:”这个方向您觉得合适吗?要不要深入看看某个部分?”
善用白板
- 从左到右、从上到下绘制架构图
- 用箭头标注数据流向
- 标注关键组件的职责
- 字迹清晰,适当使用缩写
拥抱权衡
主动说明技术选型的权衡:
plaintext
"我选择Redis缓存而不是本地缓存,是因为我们的服务部署在多个机房。
Redis缓存可以让所有实例共享一份数据,避免本地缓存导致的
数据不一致问题。但代价是增加了网络开销和Redis本身的运维成本。"
避免常见错误
❌ 不要一上来就开始画图:先理解需求和约束
❌ 不要过度设计:不需要设计能应对Google规模负载的系统
❌ 不要死磕细节:先完成高层设计,再深入细节
❌ 不要追求完美:没有完美的设计,展示你的权衡思维更重要
第五部分:学习资源推荐
书籍
入门必读:
- 《系统设计面试》—— 解题思路清晰
- 《Designing Data-Intensive Applications》—— 经典必读,深入原理
进阶扩展:
- 《大规模分布式存储系统》—— 适合深入了解存储系统
- 《构建高性能Web站点》—— 性能优化实战
在线课程
- Grokking the System Design Interview—— 经典系统设计课程
- educative.io—— 多个高质量系统设计课程
- Architecture of Open Source Applications—— 开源项目架构分析
实践平台
- LevelDB / RocksDB—— 学习 LSM 树存储引擎
- Redis—— 练习缓存和消息队列设计
- Kafka—— 理解分布式消息队列
博客与文章
- High Scalability Blog—— 大量真实系统架构案例
- System Design Primer—— GitHub 10万星资源
- System Design Interview—— 系统设计面试博客
总结
回顾我的系统设计面试经验,最重要的体会就是:系统设计没有标准答案,但有正确的方法。
面试官不在乎你选择MySQL还是MongoSQL、Redis还是Memcached,他们在乎的是:
- 你能否理解问题的本质
- 你有没有清晰的分析框架
- 你能否理性地权衡技术选型
- 你的知识广度和深度如何
与其背诵各种”标准答案”,不如真正理解每个组件的工作原理和适用场景。当你理解了这些底层逻辑,无论遇到什么题目,都能游刃有余地分析。
建议你在准备过程中,多画架构图、多写设计方案、多和朋友讨论。系统设计能力的提升,需要刻意练习和实战经验的积累。
祝各位面试顺利,拿到心仪的offer!
相关推荐
- LeetCode算法面试通关指南:2026年求职大厂的必备攻略——算法面试准备
- 大模型学习路线:从入门到实战的全方位指南——AI时代必备技能
- Go语言后端开发:2026云原生时代的高薪密码——后端开发学习路线
发表回复