
前言:为什么2026年PostgreSQL成为首选?
说实话,三年前我选数据库时,第一反应还是MySQL。毕竟用的多、资料多、社区活跃。但去年做AI应用时需要向量检索,我调研了一圈发现:PostgreSQL的pgvector扩展简直是神器,一套数据库同时搞定关系数据和向量数据,开发效率直接翻倍。
更让我惊讶的是Stack Overflow的2025年开发者调查——PostgreSQL的受欢迎程度已经超过了MySQL,差距还在持续拉大。像Instagram、Reddit、Uber、Apple这些大厂都在用PostgreSQL,它的功能和性能已经得到充分验证。
今天就把我学习PostgreSQL的经验整理出来,希望帮你少走弯路。
PostgreSQL的核心优势
- 功能强大:支持JSON、全文搜索、向量检索、地理信息等多种数据类型
- 扩展性强:可以自定义数据类型、函数、操作符,甚至用Python编写存储过程
- 标准兼容:完整支持SQL标准,事务、外键、视图、触发器应有尽有
- 性能出色:MVCC并发控制、WAL日志、查询优化器表现出色
- AI友好:pgvector扩展让PostgreSQL成为向量数据库的首选
- 开源免费:BSD许可证,完全免费商用
第一部分:PostgreSQL环境搭建
安装方式对比
PostgreSQL有多种安装方式,适合不同场景:
| 安装方式 | 优点 | 缺点 | 推荐场景 |
|---|---|---|---|
| 系统包管理器 | 简单快速 | 版本可能较旧 | 学习体验 |
| 官方安装包 | 版本新 | 配置稍复杂 | 生产环境 |
| Docker | 隔离性好 | 需要Docker基础 | 开发测试 |
| 云服务 | 免运维 | 有成本 | 生产环境 |
Windows系统安装
- 访问 PostgreSQL官方下载页
- 下载Windows安装包(约200MB)
- 运行安装程序,设置超级用户密码(务必记住!)
- 安装完成会自动启动pgAdmin管理工具
macOS系统安装
使用Homebrew安装:
bash
brew install postgresql@16
brew services start postgresql@16 # 启动服务
安装完成后,连接数据库:
bash
psql -U postgres
Docker安装(推荐开发者使用)
bash
# 拉取PostgreSQL镜像
docker pull postgres:16
# 启动容器
docker run --name my-postgres \
-e POSTGRES_PASSWORD=mysecretpassword \
-e POSTGRES_DB=mydb \
-p 5432:5432 \
-v postgres-data:/var/lib/postgresql/data \
-d postgres:16
连接与验证
使用psql命令行连接:
bash
psql -h localhost -U postgres -d mydb
或者使用pgAdmin图形化工具连接管理。
第二部分:SQL基础查询
数据库与表操作
sql
-- 创建数据库
CREATE DATABASE myapp;
-- 切换数据库
\c myapp
-- 创建表
CREATE TABLE users (
id SERIAL PRIMARY KEY,
username VARCHAR(50) UNIQUE NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL,
password_hash VARCHAR(255) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 查看表结构
\d users
-- 删除表
DROP TABLE users;
增删改查基础
sql
-- 插入数据
INSERT INTO users (username, email, password_hash) VALUES
('alice', 'alice@example.com', 'hash123'),
('bob', 'bob@example.com', 'hash456');
-- 查询数据
SELECT * FROM users;
SELECT username, email FROM users WHERE id = 1;
-- 更新数据
UPDATE users SET email = 'newalice@example.com' WHERE id = 1;
-- 删除数据
DELETE FROM users WHERE id = 2;
条件查询与排序
sql
-- WHERE条件
SELECT * FROM users
WHERE username LIKE 'a%' AND created_at > '2025-01-01';
-- ORDER BY排序
SELECT * FROM products
ORDER BY price DESC, created_at ASC;
-- LIMIT分页
SELECT * FROM users
ORDER BY created_at DESC
LIMIT 10 OFFSET 20;
聚合函数与分组
sql
-- 常用聚合函数
SELECT
COUNT(*) as total,
COUNT(DISTINCT category) as categories,
AVG(price) as avg_price,
SUM(stock) as total_stock,
MIN(created_at) as first_order,
MAX(created_at) as last_order
FROM products;
-- GROUP BY分组
SELECT
category,
COUNT(*) as count,
AVG(price) as avg_price
FROM products
GROUP BY category
HAVING COUNT(*) > 5
ORDER BY avg_price DESC;
第三部分:PostgreSQL高级特性
窗口函数——数据分析神器
窗口函数是PostgreSQL最强大的特性之一,它允许你在不分组的情况下计算聚合值:
sql
-- 排名
SELECT
name,
department,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) as dept_rank,
DENSE_RANK() OVER (ORDER BY salary DESC) as overall_rank
FROM employees;
-- 计算占比
SELECT
product_name,
sales,
SUM(sales) OVER () as total_sales,
ROUND(sales * 100.0 / SUM(sales) OVER (), 2) as percentage
FROM sales;
-- 移动平均
SELECT
date,
revenue,
AVG(revenue) OVER (
ORDER BY date
ROWS BETWEEN 6 PRECEDING AND CURRENT ROW
) as moving_avg_7d
FROM daily_sales;
JSON数据类型
PostgreSQL支持两种JSON类型:JSON和JSONB。推荐使用JSONB,因为它存储为二进制格式,查询性能更好:
sql
-- 创建JSONB列
CREATE TABLE events (
id SERIAL PRIMARY KEY,
event_type VARCHAR(50),
metadata JSONB,
created_at TIMESTAMP DEFAULT NOW()
);
-- 插入JSON数据
INSERT INTO events (event_type, metadata) VALUES
('click', '{"button": "submit", "page": "home", "user_id": 123}'),
('purchase', '{"product_id": 456, "amount": 99.9}');
-- 查询JSON字段
SELECT
event_type,
metadata->>'button' as button,
metadata->>'page' as page
FROM events
WHERE metadata->>'user_id' = '123';
-- 索引JSON字段
CREATE INDEX idx_events_user_id ON events ((metadata->>'user_id'));
全文搜索
PostgreSQL内置全文搜索功能,无需Elasticsearch也能实现高效搜索:
sql
-- 创建全文搜索列
ALTER TABLE articles ADD COLUMN search_vector TSVECTOR;
-- 生成搜索向量
UPDATE articles SET search_vector =
to_tsvector('english', title || ' ' || content);
-- 创建GIN索引
CREATE INDEX idx_articles_search ON articles USING GIN(search_vector);
-- 执行搜索
SELECT
title,
ts_rank(search_vector, query) as rank
FROM articles, plainto_tsquery('english', 'rust programming') query
WHERE search_vector @@ query
ORDER BY rank DESC;
数组类型
sql
-- 创建数组列
CREATE TABLE tags (
id SERIAL PRIMARY KEY,
name VARCHAR(50),
synonyms TEXT[]
);
-- 插入数组数据
INSERT INTO tags (name, synonyms) VALUES
('rust', ARRAY['rust-lang', 'ferrous']),
('web', '{"web开发", "frontend", "backend"}');
-- 查询数组
SELECT * FROM tags WHERE 'rust-lang' = ANY(synonyms);
-- 数组操作
SELECT array_append(synonyms, 'rustacean') FROM tags WHERE name = 'rust';
第四部分:PostgreSQL在AI领域的应用——pgvector向量数据库
这是PostgreSQL在2026年最火热的使用场景。pgvector扩展让PostgreSQL成为向量数据库,可以存储和检索嵌入向量,非常适合语义搜索、推荐系统等AI应用。
安装pgvector
sql
-- 启用扩展
CREATE EXTENSION IF NOT EXISTS vector;
-- 验证安装
SELECT extname, extversion FROM pg_extension WHERE extname = 'vector';
创建向量表
sql
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
title VARCHAR(255),
content TEXT,
embedding VECTOR(1536) -- OpenAI text-embedding-3-small的维度
);
-- 创建索引(必须!否则查询很慢)
CREATE INDEX ON documents USING HNSW (embedding vector_cosine_ops);
插入向量数据
sql
-- 插入示例向量(实际使用时需要调用AI API生成真实embedding)
INSERT INTO documents (title, content, embedding) VALUES
('Rust教程', 'Rust是一门系统级编程语言...', '[0.1, 0.2, ...]'),
('Python教程', 'Python是一门易学的编程语言...', '[0.3, 0.4, ...]');
向量相似度检索
sql
-- 查找最相似的文档(余弦相似度)
SELECT
title,
1 - (embedding <=> '[query_vector]') as similarity
FROM documents
ORDER BY embedding <=> '[query_vector]'
LIMIT 5;
-- 过滤条件 + 向量检索
SELECT
title,
content,
1 - (embedding <=> '[query_vector]') as similarity
FROM documents
WHERE created_at > '2025-01-01'
ORDER BY embedding <=> '[query_vector]'
LIMIT 3;
实际应用示例:RAG系统
sql
-- 完整的RAG查询示例
WITH query_embedding AS (
-- 这里应该调用OpenAI API生成查询向量
SELECT '[user_query_vector]'::vector as embedding
),
relevant_docs AS (
SELECT
d.title,
d.content,
1 - (d.embedding <=> q.embedding) as similarity
FROM documents d, query_embedding q
WHERE d.embedding <=> q.embedding < 0.5 -- 相似度阈值
ORDER BY d.embedding <=> q.embedding
LIMIT 5
)
SELECT
string_agg(content, ' ') as context,
similarity
FROM relevant_docs
GROUP BY similarity;
第五部分:性能优化实战
索引优化
索引是PostgreSQL性能优化的基础,但滥用索引反而会影响写入性能:
sql
-- B-tree索引(默认,最常用)
CREATE INDEX idx_users_email ON users(email);
-- 部分索引(只索引满足条件的行)
CREATE INDEX idx_active_users ON users(last_login)
WHERE is_active = true;
-- 复合索引(多列索引,注意列顺序)
CREATE INDEX idx_orders_user_date ON orders(user_id, created_at);
-- 表达式索引
CREATE INDEX idx_users_lower_email ON users(LOWER(email));
-- 重建索引(清理碎片)
REINDEX INDEX idx_users_email;
查询分析
使用EXPLAIN ANALYZE分析查询性能:
sql
EXPLAIN (ANALYZE, BUFFERS, FORMAT TEXT)
SELECT * FROM orders
WHERE user_id = 123 AND created_at > '2025-01-01'
ORDER BY created_at DESC
LIMIT 10;
关键指标解读:
- Seq Scan:全表扫描,应该尽量避免
- Index Scan / Index Only Scan:使用索引,性能好
- Bitmap Heap Scan:批量索引扫描,适合大数据量
- Buffers: shared hit:命中缓存的比例,越高越好
慢查询优化
sql
-- 查看最近最慢的查询
SELECT
query,
calls,
mean_time,
total_time,
rows
FROM pg_stat_statements
ORDER BY mean_time DESC
LIMIT 10;
-- 开启慢查询日志
ALTER SYSTEM SET log_min_duration_statement = 1000; -- 超过1秒记录
SELECT pg_reload_conf();
常见优化技巧
sql
-- 1. 使用EXPLAIN而不是EXPLAIN ANALYZE测试索引
EXPLAIN SELECT * FROM users WHERE email = 'test@example.com';
-- 2. 批量插入使用COPY
COPY users(username, email) FROM '/tmp/users.csv' WITH (FORMAT csv);
-- 3. 使用连接池(PgBouncer)
-- 安装:brew install pgbouncer
-- 配置:pgbouncer.ini
[databases]
mydb = host=127.0.0.1 port=5432 dbname=mydb
-- 4. 开启并行查询
SET max_parallel_workers_per_gather = 4;
-- 5. 调整缓存
ALTER SYSTEM SET shared_buffers = '4GB';
第六部分:学习路线与资源推荐
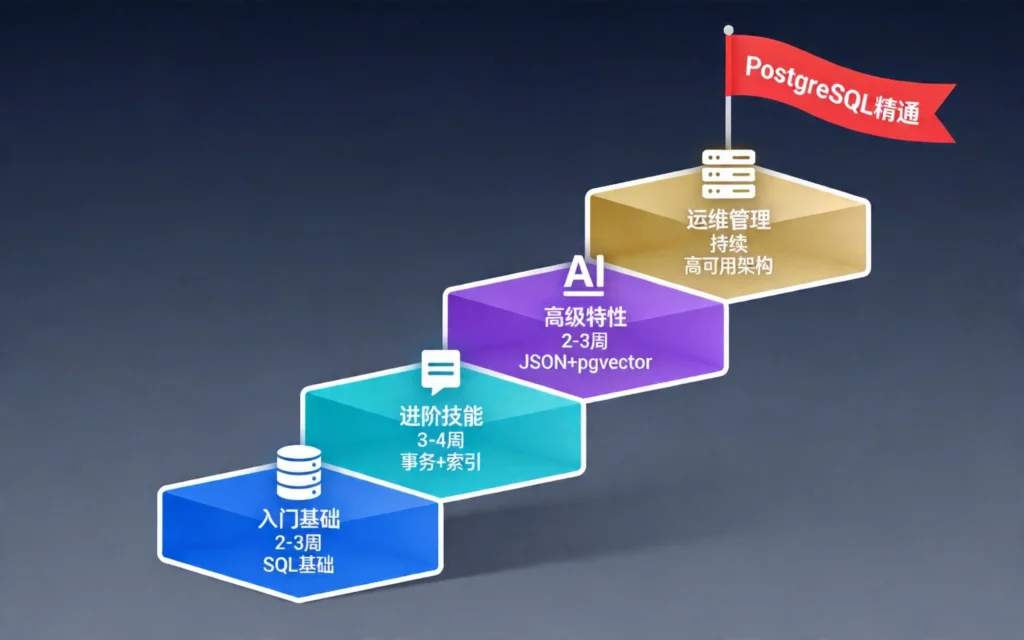
分阶段学习计划
第一阶段:入门基础(2-3周)
- 掌握SQL基础操作(CRUD)
- 理解关系型数据库概念
- 完成在线SQL练习(如SQLZoo、LeetCode SQL)
- 建议时间:2-3周
第二阶段:进阶技能(3-4周)
- 深入理解事务与锁机制
- 学习索引原理与优化
- 掌握窗口函数与CTE
- 建议时间:3-4周
第三阶段:高级特性(2-3周)
- 学习JSON、全文搜索、数组类型
- 理解MVCC与并发控制
- 掌握pgvector向量检索
- 建议时间:2-3周
第四阶段:运维管理(持续)
- 学习备份恢复策略
- 掌握高可用架构(Patroni)
- 了解云原生部署(Kubernetes)
- 建议时间:持续学习
优质学习资源
官方文档:
- PostgreSQL 16官方文档——最权威的资料
- PostgreSQL Tutorial——入门教程
- pganalyze EXPLAIN Explained——查询计划分析
书籍:
- 《PostgreSQL: Up and Running》——O’Reilly经典
- 《Mastering PostgreSQL in Application Development》
- 《The Art of PostgreSQL》
在线练习:
- SQLZoo——交互式SQL练习
- LeetCode Database——面试必备
- HackerRank SQL——分难度练习
社区与博客:
- PostgreSQL中文社区
- pganalyze Blog——性能优化专家博客
- 掘金PostgreSQL专栏
总结
学习PostgreSQL的过程让我深刻体会到:数据库不只是存储数据的地方,它是应用性能的根基。一个好的数据库设计,可以让应用性能提升10倍甚至100倍。
PostgreSQL在2026年的强大之处,不仅在于它传统的关系型数据处理能力,更在于它与现代技术的结合——pgvector让它成为AI应用的向量数据库,全文搜索让它可以替代Elasticsearch的部分场景,JSON支持让它可以处理半结构化数据。
无论你是想从事后端开发、数据工程还是AI应用,PostgreSQL都是值得深入学习的数据库。从现在开始,跟着教程动手实践,你会发现数据库的世界比想象中更加精彩。
相关推荐
- 数据分析师面试宝典:2026年求职必备指南——数据库面试题解析
- Python+AI入门实战:从零搭建你的第一个智能应用——Python与数据库结合
- Docker与Kubernetes容器化实战——数据库容器化部署
发表回复