2026年的AI应用开发岗位面试,正在经历一场静悄悄的革命。当我发现身边准备春招的朋友,个个都能把Transformer架构图画得滚瓜烂熟,把Attention机制的公式倒背如流,但面试结果却大相径庭时,我才意识到问题的关键所在:背诵八股文的时代,真的结束了。
面试官们开始追问更实际的问题:你做的RAG项目里,Chunk Size是怎么选的?Embedding模型为什么选这个?Rerank提升了多少召回率?这些问题的答案,显然不是刷几道八股文就能获得的。
本文基于2026年第一季度国内头部互联网公司和AI创业公司的数百份真实面试题,系统梳理了AI应用开发工程师面试的核心模块与实战策略。
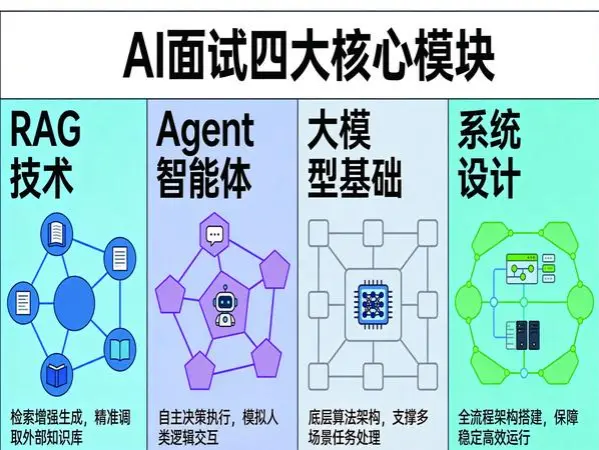
一、RAG技术:知识库问答的面试核心
RAG(检索增强生成)是2026年AI应用开发岗位出现频率最高的技术栈。无论你投的是AI应用工程师、AI开发工程师还是大模型应用工程师,RAG几乎是必考项目。
1.1 RAG基础:为什么需要RAG
面试官经常从基础问题切入:“大模型本身已经很强大了,为什么还需要RAG?”这个问题看似简单,但要答得出彩并不容易。
标准答案是:大模型存在幻觉问题和知识时效性问题。RAG通过检索外部知识库,为大模型提供最新、最准确的信息作为上下文,从而解决这两个痛点。但更深层的理解是:RAG本质上是一种将私有知识与大模型能力解耦的架构设计,让知识的更新不需要重新训练模型。
在实际项目中,我见过一个典型的场景:某金融公司需要构建智能投研助手,股票价格、财报数据每天都在更新,显然不可能每天都去微调大模型。通过RAG架构,每周更新一次向量数据库,就能让大模型获得最新的投资决策支持。
1.2 Chunk策略:面试中的高频追问
Chunk策略是RAG面试中最容易被深挖的点。基础问题可能是:“Chunk Size怎么选?Overlap设置多少合适?”
进阶追问会是这样:“你用的Embedding模型是什么?为什么选它而不是别的?”、“如果检索到的上下文和问题无关,你怎么处理?”
对于Chunk Size的选择,需要考虑两个因素:语义完整性和召回粒度。太小的Chunk会导致语义碎片化,比如一句话被切成两半;太大的Chunk会引入过多无关信息,降低召回精度。
一个实用的经验是:代码类文档建议256-512 tokens,文本类文档建议512-1024 tokens。Overlap通常设置为Chunk Size的10%-20%,既能保证上下文连续性,又不会引入太多冗余。
Embedding模型的选择也很有讲究。如果是中文文档,常见的选择包括BGE、text2vec、M3E等。如果是多语言场景,BGE-Large-zh、BGE-M3等模型表现更好。面试官真正想听到的,不是你用了哪个模型,而是你为什么做出这个选择,以及在项目中实际遇到了什么问题、怎么解决的。
1.3 Hybrid Search:提升召回率的实战技巧
Hybrid Search(混合检索)是2026年RAG优化的主流方向。面试中经常被问到:“向量检索和关键词检索有什么区别?什么时候用Hybrid Search?”
向量检索擅长语义匹配,能找到意思相近但表述不同的相关内容;关键词检索(BM25/TF-IDF)擅长精确匹配,能找到包含特定关键词的文档。当业务场景需要同时兼顾语义理解和精确匹配时,Hybrid Search就是最佳选择。
在实际项目中,我做过一个对比实验:纯向量检索Top-5结果中,有时候最相关的文档排在第3-4位。加了Rerank之后(使用bge-reranker-v2-m3),准确率提升了约20%。提到Rerank会让面试官觉得你真的做过项目,而不是简单照着教程跑了一遍。
二、Agent智能体:从概念到实践
Agent是2026年最火热的技术方向,也是面试中的高频考点。面试官想知道的不仅是你懂不懂Agent的概念,更关心你有没有实际的Agent开发经验。
2.1 Function Calling:工具调用的核心机制
Function Calling是Agent实现工具调用的关键技术。面试问题可能是:“Function Calling和传统的API调用有什么区别?”
核心区别在于:传统API调用是确定性的,参数是什么,返回就是什么;Function Calling的输出是非确定性的,大模型会根据上下文自主决定是否调用工具、调用哪个工具、传递什么参数。这意味着你需要为Agent设计容错机制,处理工具调用失败、超时、返回格式错误等各种异常情况。
在实战中,我遇到过一个大坑:大模型在特定场景下会反复调用同一个工具,形成死循环。解决方案是在Prompt中加入调用次数限制,或者在工具返回结果中增加上下文检查逻辑。面试时能说出这类具体问题,会比单纯讲概念加分很多。
2.2 ReAct框架:推理与行动的结合
ReAct(Reasoning + Acting)是Agent的主流推理框架。面试问题可能是:“解释一下ReAct框架的原理?”
ReAct的核心思想是让Agent在推理过程中交替进行“思考”和“行动”。每一步推理都会生成Thought(思考)、Action(行动)和Observation(观察),通过这种循环让Agent逐步接近目标答案。
一个典型的ReAct流程是:用户问“北京今天天气怎么样?适合穿什么衣服?”→ Thought:我需要先查询北京天气 → Action:调用天气API → Observation:北京今天晴,25度 → Thought:温度较高,适合穿轻薄衣服 → Action:返回穿衣建议。
2.3 多Agent协作:进阶面试题
多Agent协作是区分初级和高级工程师的面试分水岭。面试官可能会问:“多Agent协作怎么设计?有什么挑战?”
多Agent协作主要有两种模式:协作模式和竞争模式。协作模式下,多个Agent分工完成子任务,最终汇总结果;竞争模式下,多个Agent独立推理,通过投票或评分选择最优答案。
主要的工程挑战包括:Agent之间的通信协议设计、任务分解策略、冲突处理机制、以及如何避免循环调用。面试时能结合具体项目经验回答,会让面试官眼前一亮。
三、大模型基础:从原理到工程
大模型基础是AI应用开发工程师的必备知识。虽然不需要像算法工程师那样精通训练细节,但核心原理必须理解透彻。
3.1 Transformer架构:面试常青树
Transformer自2017年提出以来,一直是面试的常考知识点。核心问题包括:“Transformer为什么比RNN更适合处理长序列?”
关键答案是:RNN需要按顺序处理序列,无法并行计算;Transformer通过自注意力机制可以同时处理序列中的所有元素,大幅提升训练和推理速度。同时,自注意力机制可以直接计算任意两个位置之间的依赖关系,解决了RNN的长距离依赖问题。
2026年的新趋势是:纯Transformer架构正在面临长序列和效率的瓶颈。越来越多的模型开始采用Transformer与状态空间模型(SSM)的混合架构,比如Google的Gemini 2和Anthropic的Claude 3.5都在部分层中引入了Mamba-like的SSM模块,在保持Transformer性能的同时,将长序列处理的时间复杂度从O(n²)降低到了O(n)。
3.2 Token与上下文窗口
Token相关问题在2026年的面试中出现频率显著上升。常见问题包括:“Token是怎么计算的?”、“上下文窗口越大越好吗?”
Tokenization是将文本转换成数字序列的过程。不同模型有不同的分词器,中文通常1-2个汉字对应1个Token,英文1个单词可能对应多个Token。GPT-4 Turbo的上下文窗口是128K tokens,Claude 3.5支持200K tokens,但上下文窗口并不是越大越好——更长的上下文意味着更高的计算成本和推理延迟,更容易出现注意力分散的问题。
3.3 采样参数:工程实践的关键
Temperature和Top-p是控制模型输出的核心参数。面试问题可能是:“解释一下Temperature的作用?如何调参?”
Temperature控制输出的随机性:值越低,输出越确定、越保守;值越高,输出越随机、越有创意。对于代码生成、数学推理等需要精确答案的场景,建议设置较低的Temperature(如0.1-0.3);对于创意写作、头脑风暴等需要多样性的场景,可以适当提高Temperature(如0.7-0.9)。
Top-p(核采样)控制token选择的范围。Top-p=0.9意味着只从累积概率达到90%的最小token集合中选择。这种方法比传统的Top-k采样更灵活,能根据概率分布动态调整选择范围。
四、系统设计:拉开差距的关键环节
系统设计是AI应用开发面试中最能体现工程能力的环节。面试官想看到的是:你能不能把技术方案放到真实业务场景中权衡取舍。
4.1 生产级AI应用架构
面试问题可能是:“设计一个企业级知识库问答系统?”
完整的架构需要考虑:数据层(文档存储、向量数据库)、检索层(Embedding服务、检索算法)、推理层(大模型调用、Prompt管理)、应用层(API网关、监控告警)。
关键的技术选型决策包括:向量数据库选Milvus还是Pinecone?Embedding服务用本地部署还是API?大模型用GPT-4还是国产模型?这些问题没有标准答案,关键是你能不能说清楚不同方案的优缺点和适用场景。
4.2 模型网关:统一接入与成本控制
模型网关是2026年AI应用架构的新标配。面试问题可能是:“为什么需要模型网关?怎么设计?”
模型网关的核心功能包括:统一API接口、多模型路由、成本控制、限流熔断、调用日志与监控。通过模型网关,可以在一个接口后面接入多个大模型,根据业务需求和成本预算动态选择。
4.3 可观测性:上线后的必备能力
AI应用的可观测性比传统应用更复杂,因为模型的输出是不确定的。面试问题可能是:“如何监控LLM的输出质量?”
需要监控的指标包括:响应延迟、Token消耗、输出长度分布、拒绝率、幻觉率、人工评估得分等。一个实用的做法是建立黄金问答对,用自动化评测脚本定期跑回归测试,及时发现模型或Prompt的退化。
五、实战准备:从理论到表达
面试准备不仅是知识的储备,更是表达能力的训练。
5.1 项目经历的表达技巧
面试官最喜欢追问的是项目细节。建议用STAR法则组织项目经历的表达:Situation(背景)、Task(任务)、Action(行动)、Result(结果)。
更重要的是量化结果。“我优化了RAG系统的召回率”不如“我通过混合检索和Rerank优化,将Top-5召回率从72%提升到89%,相关问题回答准确率提升15个百分点”。
5.2 常见问题的应答策略
“你在项目中遇到的最大挑战是什么?”这是几乎每个面试都会问的问题。建议准备2-3个具体的技术挑战,重点说明你是如何分析问题、尝试方案、迭代优化的过程。面试官想看到的不只是你解决了问题,更是你解决问题的思维方式。
“你的职业规划是什么?”看似与技能无关,但实际上面试官在评估你对自己的认知和对行业的理解。建议结合AI应用开发的具体方向(如RAG系统优化、Agent框架开发、大模型推理加速等)来谈,展现你对行业的持续关注和学习热情。
结语
2026年的AI应用开发面试,正在从“知识测试”走向“能力评估”。面试官不再满足于你背诵了多少概念,而是更关注你能不能把技术用到真实场景中解决问题。
RAG、Agent、大模型基础和系统设计,这四大模块构成了AI应用开发工程师面试的核心框架。但框架只是骨架,真正让你脱颖而出的是:你做过的项目、踩过的坑、解决的难题。
面试准备没有捷径,但有方法。多动手实践、多思考总结、多表达复盘,当你能够在面试中流畅地分享项目经验、清晰地分析技术选型、深入地讨论工程细节时,拿下心仪的Offer就是水到渠成的事情。
祝各位在2026年的求职之路上一帆风顺!
相关资源
- Transformer原论文:Attention Is All You Need
- LangChain官方文档
- RAG评估工具:RAGAS
- 向量数据库:Milvus、Pinecone
发表回复